


Обратные вызовы в C++
distributor.addCallObject(lambda); // (5)
distributor(eventID); // (6)
auto onReturnValue = [](int callResult) {}; // (7)
distributor(onReturnValue, eventID); // (8)
}
В строке 1 инстанциирован класс распределителя с заданной сигнатурой функции. В строке 2, 3, 4, 5 в распределитель добавляются объекты вызова различного типа. В строке 6 запускается распределение вызовов, в результате которого будут вызваны добавленные объекты. В строке 7 объявлено лямбда-выражение для получения результатов, при вызове соответствующего оператора 8 это выражение будет вызвано для каждого возвращаемого значения.
Касательно модификации содержимого контейнера наш распределитель поддерживает только одну операцию – добавление получателя. Ни удаление, ни модификация получателей не поддерживается. Это связано с тем, что получатели не идентифицированы, и поэтому невозможно узнать, в каком элементе контейнера хранится соответствующий объект вызова33. Далее мы рассмотрим, как можно решить указанную проблему.
5.7. Адресное распределение
5.7.1. Понятие адресного распределения
До сих пор мы предполагали, что вызовы должны быть сделаны для всех получателей. Однако зачастую требуется распределять вызовы не всем, а только некоторым получателям из списка.
Как это реализовать? Прежде всего, необходимо как-то идентифицировать получателей, для чего вводится понятие адреса. Каждому получателю присваивается адрес, и с каждым адресом связывается универсальный аргумент, который хранит объект вызова. Таким образом, зная адреса получателей, можно осуществлять вызовы только для конкретных объектов. Попутно решается задача изменения списка получателей: по заданному адресу возможно удаление/изменение соответствующего аргумента.
Что может быть адресом? Все что угодно: числа, строки, структуры и т. п. Единственное требование, предъявляемое к адресу, заключается в том, что он должен быть уникальным, в противном случае невозможно однозначно идентифицировать получателя. Мы сделаем тип адреса параметром шаблона, а пользователь сам решит, что использовать в качестве адреса.
Теперь в функцию распределителя, помимо данных, будет передаваться адрес. Источник должен найти аргумент, которому соответствует полученный адрес, и выполнить для него вызов. Для поиска необходимо сравнивать адреса, но ведь мы не знаем их типы: теперь это параметр шаблона, и тип используемого адреса станет известен только после инстанциирования. По этой причине мы не можем производить сравнение адресов напрямую, для этого необходимо использовать предикаты (см. п. 4.3.3).
Какой выбрать контейнер? На эту роль лучше других подойдет std::map. Во-первых, не нужно вводить новую структуру для хранения адреса и аргумента, контейнер реализует ее естественным образом в виде пары «ключ-значение». И, во-вторых, std::map осуществляет быстрый поиск по ключу, в качестве которого выступает адрес. Структурная схема изображена на Рис. 25.
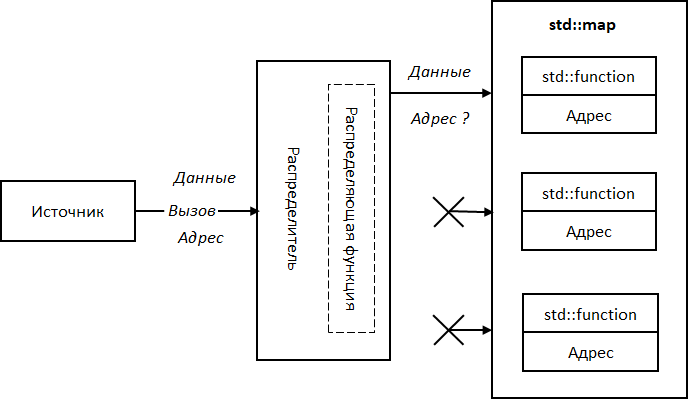
Рис. 25. Структурная схема адресного распределения
5.7.2. Адресный распределитель
Реализация адресного распределителя приведена в Листинг 84.
Листинг 84. Распределитель для адресного набора получателейtemplate
template
class AddressDistributor
{
public:
template
void addReceiver(Address address, CallObject object)
{
callObjects.insert({ address,object } );
}
void deleteReceiver(Address address) // (5)
{
callObjects.erase(address);
}
Return operator()(Address address, ArgumentList… arguments) // (6)
{
auto iterator = callObjects.find(address); // (7)
if (iterator != callObjects.end())
{
return iterator->second(arguments…); // (8)
}
else
{
throw std::invalid_argument("Invalid receiver address"); // (9)
}
}
private:
std::map< Address, std::function
};
В строке 1 объявлена общая специализация шаблона, параметрами выступают адрес получателя Address, предикат для сравнения AddressCompare и сигнатура распределяющей функции Function. Реализация здесь отсутствует, поскольку для каждой сигнатуры требуется отдельная специализация – аналогично настройке сигнатуры для универсального аргумента (п. 4.5.2).
В строке 2 объявлена частичная специализация, в которой дополнительно представлены параметр для возвращаемого значения Return и пакет параметров ArgumentList для аргументов функции. В строке 3 объявлен класс, который специализируется сигнатурой из указанных параметров.
В строке 4 объявлен шаблон метода для добавления получателя, который принимает адрес address, вызываемый объект object и добавляет их в контейнер. В строке 5 объявлен метод для удаления получателя. Оба метода работают с контейнером, который объявлен в строке 10. Контейнер объявлен как std::map, ключом является адрес, а значением – объект std::function с заданной сигнатурой.
В строке 6 объявлен перегруженный оператор, который осуществляет распределение вызовов, т. е. является распределяющей функцией. Он пробегает по всем элементам контейнера и осуществляет вызов в соответствии с списком аргументов, типы которых задаются в пакете параметров шаблона класса. Поскольку мы используем адресное распределение, т. е. предполагается, что вызов попадает только одному получателю, то мы операторе можем вернуть результат вызова.
В строке 7 происходит поиск получателя по адресу. Если получатель найден, то происходит вызов объекта (строка 8). Если получатель не найден, то генерируется исключение (строка 9), иначе какой результат нам возвратить?
5.7.3. Использование адресного распределения
Пример использования адресного распределения приведен в Листинг 85.
Листинг 85. Использование адресного распределенияstruct FO
{
int operator() (int eventID)
{
return 10;
}
};
int ExternalHandler(int eventID)
{
return 0;
}
struct ReceiverAddress // (1)
{
ReceiverAddress(int idGroup = 0, int idNumber = 0)
{
group = idGroup; number = idNumber;
}
int group;
int number;
};
template<>
struct std::less
{
bool operator() (const ReceiverAddress& addr1, const ReceiverAddress& addr2) const
{
if (addr1.group < addr2.group)
{
return true;
}
else
{
if (addr1.group == addr2.group)
return addr1.number < addr2.number;
else
return false;
}
}
};
int main()
{
int eventID = 0;
FO fo;
auto lambda = [](int eventID) { return 0; };
AddressDistributor
distributor.addReceiver({ 1,1 }, fo); // (4)
distributor.addReceiver({ 2,2 }, ExternalHandler); // (5)
distributor.addReceiver({ 3,3 }, lambda); // (6)
distributor({ 1,1 }, eventID); // (7)
distributor({ 2,2 }, eventID); // (8)
distributor({ 3,3 }, eventID); // (9)
}
В строке 1 объявлена структура для адреса, которая состоит из двух полей: идентификатор группы и номер получателя в группе. Сравнить эти две структуры напрямую нельзя, поэтому потребуется реализовать предикат.
В строке 2 объявлен функциональный объект, реализующий предикат для сравнения адресов. Почему именно в таком виде? Дело в том, что std::map требует, чтобы в качестве предиката использовался именно функциональный объект, мы не можем для этого использовать внешнюю функцию или лямбда-выражение. Это связано с тем, что в контейнере предикат хранится в виде переменной с конструктором, тип переменной определяется параметром шаблона. А наличие конструктора может обеспечить только функциональный объект.
Указанный подход имеет как достоинства, так и недостатки. С одной стороны, нам достаточно всего лишь объявить тип объекта в параметре шаблона, а затем про него можно забыть. Объект не нужно ни настраивать, ни передавать в конструктор как входной аргумент. С другой стороны, было бы удобно использовать в качестве предиката что-либо другое, например, лямбда-выражение или внешнюю функцию. Но в этом случае предикат пришлось бы инициализировать в конструкторе, причем ему нельзя было бы назначить значение по умолчанию. В любом случае, мы вынуждены следовать заданной реализации, поэтому предикат объявляем как функциональный объект.
В STL уже объявлен шаблон структуры для предикатов std::less, параметром которого выступает тип данных, которые необходимо сравнить. Этот предикат принимает на вход две переменные и возвращает true, если первая меньше второй34. std::less реализует арифметическое сравнение, поэтому для типов, которые поддерживают арифметические операции, предикат объявлять не нужно, он будет сгенерирован компилятором. Однако в нашем случае данные арифметически сравниваться не могут, поэтому мы специализируем этот шаблон своим типом (строка 2) и реализуем перегруженный оператор, который будет сравнивать две структуры. При инстанциировании контейнера компилятор сам выберет подходящую специализацию предиката, исходя из типа хранимых элементов.
В строке 3 объявлен объект распределителя путем инстанциирования соответствующего шаблона. Аргументами шаблона выступают тип адреса, предикат для сравнения и сигнатура для вызова объектов. В строках 4, 5, 6 в распределитель добавляются объекты вызова различных типов, в строках 7, 8, 9 эти объекты будут вызваны в соответствии с их адресами.
5.8. Итоги
Под распределением вызовов понимается техника, в которой при вызове единственной функции осуществляется выполнение множества вызовов через соответствующие аргументы. Структурно распределение состоит из следующих компонентов: источник, получатель, распределитель, распределяющая функция.
Если типы и количество получателей известны на этапе компиляции и не планируется их изменение в процессе выполнения программы, то мы имеем статический набор получателей. Распределитель для статического набора можно реализовать в виде функции, в этом случае распределитель структурно совпадает с распределяющей функцией.
В общем случае распределяющая функция принимает набор объектов и набор данных вызова. Эти наборы могут упаковываться в кортеж и пакет параметров в различных комбинациях. С точки зрения дизайна каждый способ упаковки имеет свои преимущества и недостатки, с точки зрения эффективности они равноценны.
Если требуются результаты выполнения вызовов, то они реализуются с помощью отдельной распределяющей функции, которая возвращает результаты в виде кортежа.
Зачастую бывает удобно реализовать распределитель для статического набора в виде класса, в котором объекты вызова хранятся в кортеже, а распределяющей функцией выступает перегруженный оператор. Здесь возникает проблема, как использовать класс с возвратом результатов выполнения и без возврата: перегруженный оператор имеет одинаковый набор входных параметров, различается только наличие и отсутствие возвращаемого значения. Выходом будет реализация двух отдельных классов либо общий класс с дополнительным параметром – индикатором. Во втором случае теряется возможность автоматического вывода типа.
Если типы и количество получателей заранее неизвестны и изменяются в процессе выполнения программы, то мы имеем динамический набор получателей. Он реализуется в виде класса с контейнером, в котором хранятся универсальные аргументы.
Если необходима передача вызовов не всем получателям, а только некоторым, то используется адресное распределение. Поскольку тип используемого адреса заранее не определен, то для сравнения адресов нужно использовать предикаты.
На этом изложение теоретического материала можно считать законченным. Далее рассмотрим, как обратные вызовы используются в практике разработки ПО.
6. Практическое использование обратных вызовов
Итак, мы изучили теоретические основы проектирования обратных вызовов, теперь пришло время продемонстрировать, как они используются в реальных системах. Для иллюстрации мы воспользуемся примером разработки модуля управления датчиками из проекта «автоматизированная система управления технологическими процессами», в котором когда-то принимал участие автор. Данный пример адаптирован, в нем опущены многие детали, которые не имеют отношения к рассматриваемой теме. Мы пройдемся через основные этапы проектирования и проследим, как обратные вызовы используются в реальных инженерных задачах.
Подробное описание всех компонентов модуля заняло бы слишком много места и навряд ли имеет практическую ценность, поэтому мы будем рассматривать самые общие принципы функционирования с акцентом на использование обратных вызовов. Полностью проект можно посмотреть здесь: https://github.com/Tkachenko-vitaliy/Callbacks/tree/master/Sensor.
6.1. Разработка архитектуры
6.1.1. Техническое задание
Первый вопрос, который должен быть задан перед началом разработки чего бы то ни было, звучит следующим образом: что мы будем разрабатывать и что мы хотим в итоге получить? Этот вопрос совсем не тривиальный, как может показаться вначале. Без ясного осознания конечной цели, без четкого понимания свойств и характеристик, которыми должна обладать проектируемая система, разработка может растянуться до бесконечности: происходят постоянные переделки, доработки, хаотичная реализация все новых и новых функций с не очень понятной ценностью, и т. п. В итоге, вместо результата мы сосредотачиваемся на процессе, а конечная цель пропадает где-то за горизонтом. Не сталкивались с такими проектами? Что ж, вам крупно повезло; чтобы также везло в дальнейшем, и подобные проекты в вашей карьере отсутствовали, любое проектирование нужно начинать с постановки целей, которые выражаются в требованиях, предъявляемых к системе. В нашем случае они будут следующими.
Разработать модуль управления датчиками, который должен обеспечивать:
1. Настройку конфигурации датчиков и возможность ее изменения в процессе работы.
2. Отслеживание состояния и определение неисправности датчиков.
3. Считывание показаний отдельных датчиков.
4. Считывание показаний всех работоспособных датчиков.
5. Асинхронный опрос показаний.
6. Возможность получения минимальных и максимальных значений для группы датчиков.
7. Настройка пороговых значений показателей и уведомление при их превышении.
8. Возможность работы как с реальными физическими датчиками, так и с их программными моделями.
6.1.2. Сценарий функционирования
Базовый сценарий функционирования модуля следующий.
Основным компонентом, поставляющим информацию, являются датчики. Они могут производить измерения трех типов: текущее, сглаженное и производное. Для идентификации датчикам присваиваются уникальные номера.
Перед началом работы производится настройка, т. е. определяется состав датчиков, с которых будут сниматься показания. Настройка не статическая, она может изменяться в процессе работы.
В любой момент приложение может запросить показания датчиков как в синхронном, так и в асинхронном режиме. Показания возвращаются только для функционирующих датчиков, в приложении должна иметься возможность проверить их работоспособность.
Коммуникация с датчиками осуществляется через протокол USB либо Ethernet путем пересылки / получения команд в соответствии с заданным протоколом.
В процессе работы модуль должен отслеживать и уведомлять приложение о том, что некоторые показатели превышают заданные пороговое значение. Состав измеряемых значений и их предельные величины настраиваются приложением.
В соответствии с описанием структура системы может быть представлена следующим образом (Рис. 26).
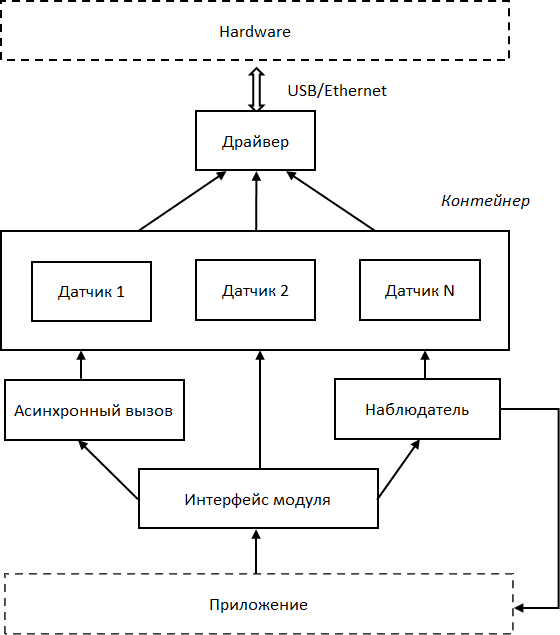
Рис. 26. Структурная схема
Приложение через интерфейс обращается к функциям модуля. В зависимости от вызываемой функции интерфейс обращается к соответствующим компонентам и возвращает результат.
Компонент «Асинхронный вызов» предназначен для выполнения асинхронных вызовов. «Наблюдатель» предназначен для отслеживания пороговых значений. «Контейнер» хранит список датчиков. Компонент «Датчик» через компонент «драйвер» обращается к аппаратному обеспечению.
6.1.3. Декомпозиция системы
Итак, в соответствии методологией объектно-ориентированного анализа необходимо определить состав классов и связи между ними, отражающие предметную область. Нам будут необходимы следующие классы:
• класс для работы с датчиком;
• контейнер для хранения указанных классов;
• драйвер, обеспечивающий низкоуровневое взаимодействие с аппаратурой;
• очередь для выполнения асинхронных запросов;
• класс для отслеживания пороговых значений;
• интерфейсный класс, который будет взаимодействовать с приложением для вызовов соответствующих функций модуля.
Обобщенная диаграмма классов модуля представлена на Рис. 2735.
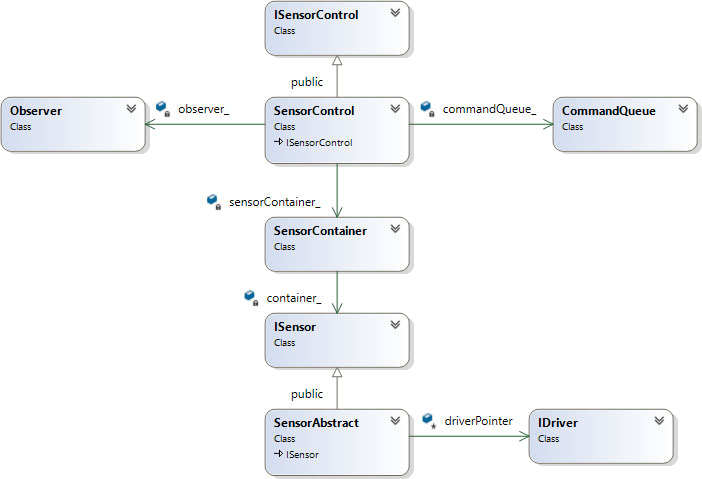
Рис. 27. Обобщенная диаграмма классов
Класс ISensorControl объявляет интерфейс модуля, класс SensorControl реализует указанный интерфейс. SensorControl содержит классы Observer (отслеживает пороговые значения), CommandQueue (очередь комманд для асинхронных запросов), SensorContainer (реализует контейнер для хранения классов для работы с датчиком).
Интерфейс для работы с датчиками объявлен в классе ISensor, обощенная реализация интерфейса осуществляется в классе SensorAbstract. Указанный класс хранит указатель на IDriver, который используется для получения значений датчиков. В классе IDriver объявляется интерфейс для взаимодействия с аппаратурой.
6.2. Реализация классов
6.2.1. Общие определения
В Листинг 86 представлены общие объявления типов.
Листинг 86. Общие объявления типов (SensorDef.h)namespace sensor
{
class ISensor;
class IDriver;
using SensorNumber = unsigned int; // (1)
using SensorValue = double; // (2)
using CheckAlertTimeout = unsigned int; // (3)
enum class SensorType : uint32_t // (4)
{
Spot = 0,
Smooth = 1,
Derivative = 2,
};
enum class DriverType : uint32_t // (5)
{
Simulation = 0,
Usb = 1,
Ethernet = 2
};
enum class AlertRule : uint32_t // (6)
{
More = 0,
Less = 1
};
using SensorPointer = std::shared_ptr
using DriverPointer = std::shared_ptr
using SensorValueCallback = std::function
using SensorAlertCallback = std::function
}; //namespace sensor
В строке 1 объявлен тип для номера датчика, в строке 2 объявлен тип значения, возвращаемого датчиком. В строке 3 объявлен тип значения интервала опроса датчиков для сигнализации пороговых значений.
В строке 4 объявлены идентификаторы типов датчиков, в строке 5 объявлены идентификаторы драйверов. В строке 6 объявлены идентификаторы правил для задания пороговых значений (сигнализация превышения или опускания ниже заданного значения).
В строке 7 объявлен тип для хранения указателей классов датчиков, в строке 8 – тип для хранения указателей классов драйверов. В строке 9 объявлен тип обратного вызова, в который передается значение датчика, в строке 10 – тип обратного вызова, в который передается значение датчика в случае срабатывания сигнализации порогового значения.
6.2.2. Обработка ошибок
В процессе работы любой программы могут ситуации, приводящие к ошибкам. Причины ошибок могут быть самыми различными: неправильные действия пользователя, некорректная работа ПО, сбои в работе оборудования и т. п. Таким образом, возникает необходимость реализации подсистемы обработки ошибок, которая осуществляет восстановление работоспособности компонента после возникновения ошибочной ситуации и уведомление об этом пользователя.
В общем случае существуют две модели обработки ошибок: анализ кодов возврата и использование исключений. Несмотря на то, что использование исключений в последнее время подвергается серьезной критике, вплоть до того, что в новых языках программирования от них избавляются, в C++ указанный механизм остается востребованным, и мы также им воспользуемся. Объявления для формирования исключений представлены в Листинг 87.
Листинг 87. Исключения для обработки ошибок (Errors.h)namespace sensor
{
enum class SensorError: uint32_t // (1)
{
NoError = 0,
NotInitialized = 1,
UnknownSensorType = 2,
UnknownSensorNumber = 3,
SensorIsNotOperable = 4,
DriverIsNotSet = 5,
InvalidArgument = 6,
NotSupportedOperation = 7,
InitDriverError = 8
};
class sensor_exception : public std::exception // (2)
{
public:
sensor_exception(SensorError error);
SensorError code() const;
virtual const char* what() const;
static void throw_exception(SensorError error); // (3)
private:
SensorError code_;
};
}; //namespace sensor
В строке 1 объявлены коды возможных ошибок, в строке 2 объявлен класс исключений. Если при выполнении где-то в коде возникает ошибка, то в этом месте нужно вызвать метод, объявленный в строке 3. Указанный метод выбросит исключение с соответствующим кодом.
6.2.3. Драйвер
Драйвер предназначен для взаимодействия с аппаратным обеспечением. Класс, представляющий обобщенный интерфейс для работы с драйвером, приведен в Листинг 88.
Листинг 88. Интерфейс для работы с драйвером (DriverInterface.h)namespace sensor
{
class IDriver
{
public:
virtual void initialize() = 0; // (1)
virtual void activate(SensorNumber number) = 0; // (2)
virtual bool isOperable(SensorNumber number) = 0; // (3)
virtual SensorValue readSpot(SensorNumber number) = 0; // (4)
virtual SensorValue readSmooth(SensorNumber number) = 0; // (5)
virtual SensorValue readDerivative(SensorNumber number) = 0; // (6)
virtual ~IDriver() = default;
static DriverPointer createDriver(DriverType type); // (7)
};
}; //namespace sensor
В строке 1 объявлен метод для инициализации драйвера. В строке 2 объявлен метод для активации датчика. В строке 3 объявлен метод, возвращающий признак работоспособности датчика. В строках 4, 5 и 6 объявлены методы для чтения соответственно текущих, сглаженных и производных значений. Метод в строке 7 представляет собой фабрику классов, в котором происходит создание класса соответствующего типа.
От общего интерфейса наследуются классы, реализующие драйверы различных типов. В нашей системе реализованы три типа драйверов: драйвер для работы с шиной USB; драйвер для работы через сеть Ethernet; имитируемый драйвер. Диаграмма классов изображена на Рис. 28.
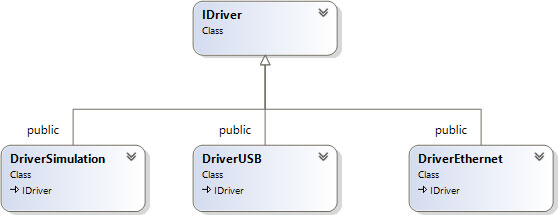
Рис. 28. Диаграмма классов, реализующих драйверы