Последний отзыв

Книга дельная. Без воды, приводятся реальные кейсы и способы их разрешения. Много практичных полезных советов и методик. Кое-что уже испробовала в дел...
Далее
По всем вопросам обращайтесь на: info@litportal.ru
(©) 2003-2025.
✖



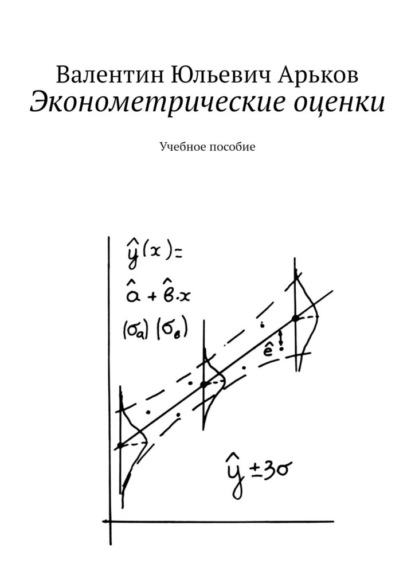
Эконометрические оценки. Учебное пособие
Настройки чтения
Размер шрифта
Высота строк
Поля
Теория объясняет общие законы природы. Там, где есть случайность, можно говорить о вероятности события.
Вероятность обозначается латинской буквой p. Это первая буква английского слова probability. Происходит от латинского слова proba – «пробовать, проверять». Получается, что один раз попробовал что-то сделать – получилось, в другой раз попробовал – не получилось. Когда мы что-то пробуем, появляется случайность, неопределённость, непредсказуемость. И вероятность – это частота события, насколько часто происходит то, что нас интересует.
Русское слово «вероятность» имеет отношению к слову «верить». И это вторая сторона вероятности: насколько мы доверяем какому-то сообщению, утверждению, прогнозу.
Рис. Вероятность: теория и оценка
Теория – это всегда красиво и всегда «точно». Теория вероятности говорит нам: если шансы равны, то вероятность будет ровно 0,5 для орла и ровно 0,5 для решки. Это абсолютно «точное» значение – никаких сомнений. Но с одной оговоркой: если шансы равны, см. рис.
Статистика – это фактические данные. Когда мы переходим к обработке данных, то никогда не видим идеальные числа и идеальные условия. Мы каждый раз видим реальные наборы данных. Например, тысячу раз бросили монетку. Посчитали, сколько раз выпал орёл. Представим, что из десяти тысяч раз почти в половине случаев монетка упала орлом вверх. Делим на общее число бросаний и получаем число, которое будет приближаться вот к теоретическому значению.
Это число называется ОЦЕНКА. Оценки часто обозначают символом «крышечка» или «крышка». Настоящая вероятность и оценка по реальным данным приблизительно соответствуют друг другу, но только ПРИБЛИЗИТЕЛЬНО. Оценку мы можем посчитать: берём реальные данные и считаем. Такие опыты были в истории. В книгах можно найти упоминание о том, как ещё до появления компьютеров математики решили проверить свои теории. Они 10 тысяч раз бросали монетку. Можете представить, какая это работа. Бросать монетку и каждый раз записывать результат на бумаге, а потом вычислить оценку вероятности.
Рис. Эксперименты и оценки
Вот в чём разница между теорией и обработкой данных. Теория говорит нам, как всё должно быть в принципе, при идеальных условиях. На практике мы берём реальные данные и обсчитываем то, что получили. Если у нас были разумные предположение, то результаты будут соответствовать теории.
Когда мы говорим о реальных данных, опыт с монеткой можно провести «физически» – действительно бросать монетку много раз. Есть и другой вариант – использовать программный генератор случайных чисел. В этом случае мы имеем дело с тем, что называется ИМИТАЦИОННОЕ МОДЕЛИРОВАНИЕ. Это целая технология, но мы с вами затронем эту область только для того, чтобы увидеть, как это происходит. Мы будем моделировать идеальные, красивые данные, на которых можно тренироваться. Потом, на лабораторных работах можно будет взять реальные, настоящие данные. Они уже не такие «красивые». Они могут быть «корявыми», «неправильными», какими угодно. Но они чем-то будут напоминать нашу теорию и наши результаты.
В любом случае, мы можем взять реальные данные или результаты моделирования. То, что мы по ним посчитаем, каждый раз будет называться ОЦЕНКА. Оценка – это очень приблизительное значение, которое может соответствовать настоящему, теоретическому.
Есть разные способы моделирования, генерирования, создания случайных чисел. Пока в качестве инструмента для работы мы обсуждаем табличный редактор – Excel или его аналоги. Первый вариант – генератор случайных чисел в настройке «Анализ данных», см. рис.
Рис. Моделирование с помощью надстройки
Мы просто генерируем столбец чисел и определяем вероятность того, что выпадет орёл. В нашем случае получилось значение 0,522. Мы как бы «бросали монетку» заданное количество раз. Генератор случайных чисел создаёт число от нуля до единицы. Эти числа имеют равномерное распределение, то есть у нас одинаковые шансы (вероятность) появления любого числа от нуля до единицы. Далее мы берём полученное число и используем функцию округления. Как вы знаете, обычно округляют по стандартному правилу. Если число меньше 0,5 – округляем в меньшую сторону и пишем 0. Если число больше 0,5 – округляем в большую сторону и пишем 1. Таким образом, мы половина чисел округляется до нуля, а другая половина чисел округляется до единицы. Если ровно 0,5 – то в большую сторону.
Напомним, что есть как минимум шесть методов округления компьютера. Это обсуждается в курсе «Средства вычислительной техники». Можете жтот материал ещё раз посмотреть. В нашем примере мы используем для округления функцию ROUND / ОКРУГЛ.
Excel – надстройка
Запускаем табличный редактор Excel.
Делаем заголовок – это наши «иксы».
Вызываем надстройку: Данные – Анализ данных. В диалоговом окне выбираем генератор случайных чисел.
Рис. Общий план демонстрации
Задаём число переменных. Имеется ввиду число столбцов. В электронных таблицах каждая переменная – это, прежде всего, столбец. Это же касается и баз данных – там тоже есть таблицы, и данные в таблицах тоже расположены по столбцам. Нас интересует одна колонка случайных чисел. Пускай у нас будет 10 тысяч значений.
В разделе «Распределение» выбираем Uniform / Равномерное.
Диапазон значений от 0 до 1.
Параметр Random seed в русском переводе звучит как «Случайное рассеивание». На самом деле, это НАЧАЛЬНОЕ СОСТОЯНИЕ ГЕНЕРАТОРА. Этот параметр задаётся целым числом. Мы в качестве примера напишем 1234.
Диапазон для вывода результатов – Output range. Мы говорим, что надо выводить случайные числа, начиная с указанной ячейки.
Машина немного подумает и сгенерирует нам заданное количество случайных чисел.
После этого мы их округлим и посчитаем вероятность нашего события.
Событие А заключается в том, что у нас выпала единичка. Мы пишем ROUND, даём ссылку на соседнюю ячейку и говорим: ноль знаков после запятой.
Рис. Моделирование нулей и единиц
Конечно, есть некоторые сомнения по поводу округления числа, равного точно 0,5. Проделаем опыт: напишем 0,5 и округлим.
Сделаем откат и возвращаемся к исходным данным.
Теперь нам предстоит заполнить второй столбец. Берём правый нижний уголок ячейки – это маркер автозаполнения. Дважды щёлкаем по нему – и вся колонка заполняется нулями и единицами. Чтобы это проверить, нажимаем [Ctrl+Down]. Перемещаемся самый низ нашего столбца – в последнюю заполненную ячейку. Мы видим 10001 строку. Это последняя строка. Возвращаемся в начало: [Ctrl+Home].
Теперь подсчитаем вероятность. Я напомню, что это только оценка вероятности. Поскольку наши данные – это нули и единицы, оценка вероятности – это среднее значение по столбцу А. Среднее значение в английском варианте Excel называется AVERAGE, в русском варианте – СРЗНАЧ. Указываем диапазон ячеек: щёлкаем первую ячейку, затем нажимаем комбинацию клавиш [Ctrl+Shift+Down]. Мы отметили все ячейки. Нажимаем клавишу [Enter] или [Ввод].
Вот наш результат – мы получили число, которое очень близко к 0,5. Но это не ровно 0,5. Просто достаточно близко к теоретическому значению.
В чём особенность этого метода? Мы генерируем числа с помощью надстройки. Если мы хотим сгенерировать новый набор данных, нам нужно будет снова вызвать «Анализ данных». Мы вызываем генератор, задаём новое состояние генератора, нажимаем [OK]. Нас предупреждают, что ячейки вообще-то заняты предыдущими числами. Машин подумает и заполнит наши 10 тысяч ячеек. Обратим внимание на новую оценку вероятности.
Такой эксперимент вам предстоит проделать несколько раз – в рамках знакомства с данным материалом.
Подведём итоги. Мы вызвали генератор случайных чисел с помощью надстройки, установили равномерное распределение, округлили и нашли оценку вероятности – как среднее из нулей и единиц. Что это значит применительно к нашей формуле? В числителе находится количество единиц – это число событий, которые нас интересуют. В данном случае сумма единиц – это количество событий, когда выпал орёл. В знаменателе – общее количество событий. В нашем примере это 10000. Так что если у нас нули и единицы и мы считаем среднее из этого количества данных, мы автоматом получаем оценку нашей вероятности. Она называется ЧАСТОТА.
Если оценка вероятности получена по реальным данным, её называют частотой. Конечно, это просто количество – в отличие от физики. В физике частота – это число событий в единицу времени или число оборотов в единицу времени. В физике частоту измеряют в Герцах, а в статистике – в «единицах», в «штуках», в количестве объектов или событий. Так что это частота в разном понимании.
Excel – функция
Есть и другой способ генерирования случайных чисел. Это готовая функция RAND / СЛЧИС. Мы его тоже можем разобрать. Внешне всё будет выглядеть точно так же, как в предыдущем примере: столбец «иксов» и столбец нулей и единиц, затем оценка частоты, то есть вероятность, см. рис.
Рис. Демонстрация генератора-функции
Здесь есть некоторые тонкости.
Чтобы взять содержимое одной ячейки и заполнить диапазон ячеек, можно просто взяться за уголок маркера и протянуть вниз. Но чтобы дотянуть до ячейки под номером 10001, придётся потратить пару минут. А теперь представьте, что нужно скопировать формулу в миллион ячеек. Такое заполнение – надолго. Да ещё можно промахнуться.
Но не всё так плохо. У нас в запасе есть другой приём: мы вводим формулу в одну ячейку, затем указываем в окошке адреса ячейки нужный диапазон А2:А10001. В результате мы выделяем этот диапазон. Затем в верхнем меню выбираем Home – Editing – Fill – Down. Это означает «заполнить вниз от текущей ячейки». Так мы заполняем столбец нужного размера, см. рис.
Рис. Заполнение столбца
Вторую колонку мы заполняем с помощью маркера автозаполнения – как в первом примере.
Рис. План демонстрации
Начнём демонстрацию. Переходим в Excel. Создаём новую страничку. В первой колонке у нас находится «икс». Мы пишем RAND и пустые скобки. Это функция без параметров. Она создает нам одно случайное число. Щёлкаем по ячейке. В окне адреса укажем диапазон адресов от А2 до А10001. Видим, что у нас выделился диапазон. Дальше нужно его заполнить: Home – Editing – Fill – Down. Мы заполнили весь диапазон. Можем проверить [Ctrl+Down]. Переходим в последнюю ячейку А10001, дальше ничего нет.
Нас интересует событие А. Мы пишем ROUND. Обратите внимание, что первый столбец автоматически пересчитывается. Округляем ячейку A2, ставим запятую и ноль. В русском варианте аргументы функции разделяются другим значком (точка с запятой), потому что в русском варианте символ запятой – это десятичный разделитель. Он разделяет целую и дробную части числа. Двойной щелчок по маркеру автозаполнения – получили столбец нулей и единиц.
Находим нашу частоту, то есть оценку вероятности случайного числа 0,5. Вызываем функцию AVERAGE.
Другие электронные книги автора Валентин Юльевич Арьков




Последний отзыв
Книга дельная. Без воды, приводятся реальные кейсы и способы их разрешения. Много практичных полезных советов и методик. Кое-что уже испробовала в дел...
Далее