


Менеджмент цифрового мира
Отметим, что часть из перечисленных выше проблем представляют собой примеры тех или иных потерь (waste) в рабочем процессе, то есть работ, не несущих ценности: согласовать без необходимости, сделать оказавшееся ненужным, переделывать ранее сделанное и так далее. В IT-разработке и в любой другой интеллектуальной работе потери тоже присутствуют, как и в физическом производстве, просто они носят другой характер, поэтому производственный lean напрямую не применим. А задача метрик – наблюдать за ходом процесса и потерями, и служить сигналом, что какие-то из них превысили допустимый объем и требуют устранения.
Отмечу, кстати, что встречаются очень простые потери, связанные с незнанием приемов эффективной работы с текстами на компьютере. Наверное, все вспомнили про 10-пальцевую слепую печать. Это верно, но лишь отчасти: слепая печать очень актуальна, когда человек перепечатывает готовый текст, а это встречается относительно редко. В остальных случаях достаточно успевать вводить лишь со скоростью своей мысли. А вот владение hotkey, особенно при работе с буфером обмена для быстрого переноса текстов, чтобы не надо было переключаться на мышь – гораздо важнее. Почему-то на это не обращают должного внимания. А очень жалко наблюдать, как люди медленно делают то, что можно сделать гораздо быстрее… Впрочем, я отвлекся от рассказа про метрики.
Agile-методы предъявляют к метрикам и их визуализации особые требования: работа с ними перестает быть уделом избранных, а становится предметом заботы всех членов команды. А это означает наглядное представление, позволяющее быстро провести анализ ситуации по графикам, с тем, чтобы возникла эмпатия к графикам, подобная эмпатии к доске. Scrum решил такую задачу в частном случае, там придумали burndown chart.
В Kanban тоже есть несколько хороших визуальных представлений. Одно из них – кумулятивная диаграмма потока, на которой каждый день по вертикали откладывают число задач, находящихся на каждой стадии, как показано на рисунке. В результате по горизонтали мы можем увидеть, сколько времени в среднем занимает каждая фаза и, в том числе выделить непропорционально большие фазы, как это показано на приведенном примере диаграммы, на котором видно, что задачи очень долго отлеживаются на согласовании у CEO. Пример взят из уже упоминавшегося выше доклада Алексея Пименова на AgileDays-2019 «Скрытая механика работы Kanban Method».

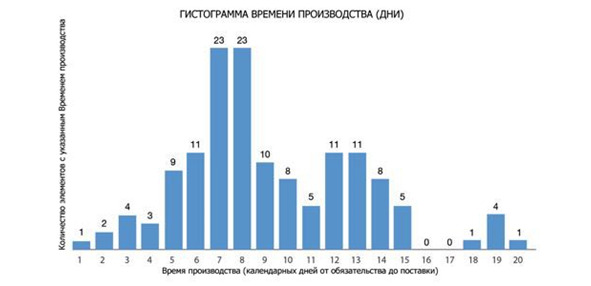
Другая полезная диаграмма – частотная диаграмма. По горизонтали откладываем срок выполнения задач в днях, по вертикали – число таких задач. Диаграмму строим в разрезе классов обслуживания, выделенных в SLA. Если задачи в потоке однородны, то мы получим пуассоново распределение или его аналог. А вот если у полученного распределения есть несколько максимумов, то значит мы имеем дело с существенно неоднородным потоком задач. В этом случае имеет смысл провести анализ, чтобы научиться заранее разделять классы задач и с этой помощью улучшить предсказуемость их выполнения и учесть это в SLA. Потому что предсказуемость для бизнеса часто имеет гораздо большее значение, чем скорость.
Это все – конкретные примеры, и их можно приводить довольно долго. Но это именно примеры, а не универсальная система метрик. Конечно, было бы очень привлекательно получить именно универсальную систему, однако опыт развития IT говорит о том, что ее не существует. Однако, выработка системы метрик для конкретной компании или конкретной команды – вполне обозримая задача, есть много разных докладов на конференциях о конкретных системах метрик. И основную ценность в них представляет не конкретная система метрик, а логика, в которой к ней шли. Собственно, это – частное проявление пути Kanban: мы внедряем не конкретный процесс, а запускаем эволюционное развитие процесса, в данном случае – экспериментируя с разными метриками и индикаторами для повышения предсказуемости работы и мониторинга здоровья. На этом я закончу разговор метриках.
Каденции и синхронизация
Как известно, в Scrum со спринтом связан ряд встреч: daily scrum, планирование, демо, ретро, а помимо них есть и другие встречи, такие как story mapping для планирования релизов. Все они обеспечивают синхронизацию процесса и взаимодействие со стейкхолдерами. Как легко догадаться, эти функции являются необходимыми для организации потока создания ценности и должны быть выполнены при любом способе организации процесса. В Kanban для выполнения этих функций используются каденции – регулярные встречи, каждая из которых посвящена определенному вопросу и имеет свой собственный ритм, зависящий от соответствующего потока работы.
Выделяется семь типов каденций, связанных с различными фокусами внимания.
– Статус-митинг, как правило, ежедневный для обсуждения текущих задач и решений по заблокированным задачам.
– Пополнение списка задач – обсуждение, какие именно задачи сейчас являются наиболее приоритетны и должны быть включены в работу. Обычно раз в 1—2 недели.
– Планирование поставки – представление сделанного и передача результата клиентам
– Обзор качества сервиса и способов его улучшения.
– Операционная встреча по качеству взаимодействия со смежниками.
– Обзор рисков, связанных с блокировками выполнения задач и их влиянием на работу сервиса.
– Обзор и обновление стратегии.
Заметим, что все они в том или ином виде есть в Sсrum, только привязаны к спринту, за исключением последней.
Однако, Kanban не диктует, что в процессе обязательно должно быть семь описанных выше серий встреч. Набор конкретных встреч зависит от конкретных условий работы. Например, если команда взаимодействует с разными смежными подразделениями, например, юристами и HR по совершенно разным вопросам и в разном темпе, то это можно обсуждать на разных сериях встреч. Если подразделение предоставляет сервис нескольким разным клиентам с разными циклами поставки, то эти встречи могут проводиться независимо. Более того, далеко не все встречи необходимы. Например, по пополнению может быть принято решение, что каждый стейкхолдер ведет свой список срочных задач, а выбор задач для выполнения происходит по очереди, и специальная встреча назначается, только если этот порядок надо нарушить.
Таким образом, к описанному выше списку стоит относиться, скорее, как к списку важных фокусов, которые, как показывает опыт, стоит держать под контролем тем или иным образом. При этом, что важно, каждый из фокусов надо держать отдельно, и потому смешивать их на одной встрече не слишком желательно, даже если состав участников совпадает. Дэвид Андерсон в своей книге показывает, как эти механизмы возникали в его командах по мере эволюционного развития процесса, и как менялась их форма. Делать это в форме отдельных серий встреч – самый простой способ, но вовсе не обязательный. И в любом случае, встречи появляются постепенно, при чем порядок тоже может быть различен. Подробнее об этом узнать в докладе Алексея Пименова на AgileDays-2018 «Канбан! Что новенького?» В отличие от его доклада на AgileDays-2019, на который я ссылался в начале статьи, этот дает обзор новых техник и рассчитан на более глубокий уровень слушателя.

Масштабирование
Первоначально Kanban-система часто проектируется и внедряется для отдельного подразделения, выбранного в качестве пилотной площадке. Далее она может распространяться на смежные подразделения по цепочкам создания ценности, а также вверх на компанию, для организации потока ценности в целом.
Существует и другой способ внедрения, применяемый в ситуации, когда каждое подразделение работает более-менее нормально, однако в целом поток создания ценности буксует на взаимодействии между ними. В этом случае внедрение может быть начато сверху, для получения крупной картины, и для начала проявлена передача крупных задач между подразделениями и их взаимодействие. Способ работы отдельных подразделений и команд при этом может быть сохранен. Такая конструкция может применяться, в частности, для оркестрации работы отдельных Scrum-команд, если из них выстроены длинные цепочки создания ценности с взаимными зависимостями.
Отметим, что при масштабировании Kanban-системы на компанию в целом или на автономные бизнес-единицы помимо метрик, показывающих прохождение потока задач становятся актуальными метрики, показывающие финансовые результаты деятельности. Естественным желанием является взять готовую систему стандартных финансовых метрик. Засада в том, что не всякая система метрик является совместимой с теорией ограничений, которая лежит в основе Kanban. Это подробно разобрано в книге Томаса Корбета «Учёт прохода. Управленческий учет по теории ограничений» (оригинал называется «Throughput accounting», есть русский конспект). И может получиться, что оптимизация потока оценивается метриками и KPI негативно. Эту опасность необходимо представлять, и выбирать метрики правильно.
На встречах по анализу процесса, на основе анализа метрик выполняется выявление проблем и поиск способов их решения. При этом предпочтение отдается эволюционному пути: если есть проблема во взаимодействии двух подразделений, то для начала стоит наладить коммуникацию по рабочим вопросам и регулярный анализ взаимоотношений. Но если проблема носит системный характер, то, возможно, стоит подумать о перестройке цепочек создания ценности с переходом от длинных цепочек к коротким, о котором я писал в предыдущей главе.
Фреймворки масштабирования Agile на компанию
Ячейкой организации в любом случае является автономная самоорганизующаяся Agile-команда, поэтому совместимость способов управления с Agile-культурой является принципиальным требованием. Опыт показывает, что многие подходы менеджмента, основанные на уважении авторитета руководителя, полагаемого безусловным, или следовании за непогрешимым лидером не выдерживают столкновения с Agile-культурой: сотрудники могут просто уйти целой командой. И если руководство привыкло к такому стилю управления, то в Agile нет никакого смысла. С другой стороны, как я говорил в главах «Три вызова цифрового мира» и «Цифровой мир: от физического труда – к умственному» методы регулярного менеджмента в цифровом мире перестают работать, а Agile-методы являются одной из работающих альтернатив, что подробно рассмотрено в главе «Agile – ответ IT на вызовы цифрового мира».
Фреймворки имеют разную сложность и рассчитаны на компании или подразделения разного размера. При этом большинство из них рассчитано на короткие цепочки создания ценности, когда одна кроссфункциональная команда делает продукт, поставляемый потребителям. Как я писал в главе «Место Agile-команд в компании», в условиях неопределенности и быстрого изменения условий работы компании в VUCA-мире короткие цепочки являются естественным способом организации труда, способным быстро реагировать на изменения, в отличие от стабильных условий функционирования, которые ведут к специализации и образованию длинных цепочек из функциональных подразделений.
Большинство фреймворков, о которых я буду говорить, ориентированы на обеспечение только основной операционной работы компании. Однако, следует учитывать, что границы ответственности команд могут быть существенно различны. Достаточно распространенной является практика, когда в ответственность команд передается найм и увольнение сотрудников, их обучение, а также финансовая ответственность за создаваемый продукт, то есть команда становится независимым подразделением. В других случаях HR остаются независимым подразделением, так же как бухгалтерия и юридическая служба, и тогда их работа может быть организована как сервисная инфраструктура для команд, работающая по Kanban или одним из гибридных Agile-методов. Сохранение традиционной организации тоже возможно, однако, важно обеспечить хорошее качество сервиса и не служить препятствием для движения команд основного операционного контура. И перед тем, как перейти к обзору фреймворков я хочу порекомендовать доклад Асхата Уразбаева «Фреймворки масштабирования Agile» на SECR-2017 со сравнением разных фреймворков.

Простые фреймворки: Scrum of Scrum, Nexus, LeSS
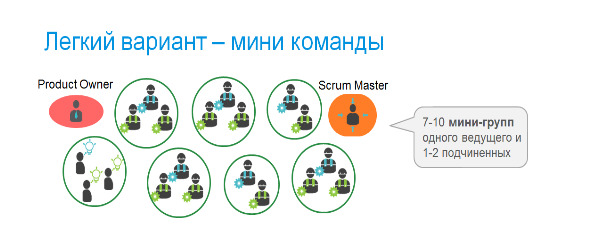
Начну я с наиболее простого Scrum of Scrums, который появился раньше других. Он применяется в случае, если у вам в компании есть независимые Scrum-команды, каждая из которых делает свой продукт. Тогда для работы надо общими вопросами достаточно собрать команду Product Owner для обсуждения стратегии развития продуктов и координации усилий, и команду Scrum Master для обсуждения и координации вопросов организации. Если в командах есть Tech Lead, отвечающий за технологии и обучение им сотрудников, то добавляется еще координирующая команда из них. Однако, бывают ситуации, когда одна команда не может обеспечить развитие продукта в требуемой темпе, ее мощности не хватает. Ведь размер команды ограничен, эффективно работает команда в 7—9 человек, а если их становится сильно больше, то необходимо дополнительное структурирование. Есть относительно простой способ нарастить команду до 15—20 человек, представленный на схеме. Это конструкция из мини-команд, каждая из которых состоит из опытного сотрудника и 1—2 стажеров, для которых опытный является наставником для стажеров. При этом операционные вопросы взаимодействия решаются командой из руководителей мини-команд.
Другой относительно простой способ – это собрать Integration Team из представителей отдельный команд, которая будет решать вопросы координации и зависимостей. Это предлагает Nexus и достаточно в случае, когда зависимости являются достаточно слабыми.
Более сложный фреймворк – Large Scaled Scrum (LeSS) (русское описание) – несколько команд на одном продукте с общим Product Owner, BackLog, спринтами, планированием, демо и поставкой, это позволяет объединить до 8 команд. У фреймворка есть huge вариант, применяемый для больших компаний и рассчитанный на работу 1000+ человек.
Spotify
Ответственность команды не ограничивается выполнением основных производственных задач, она имеет много планов и фокусов, и логично, когда это реализуется через отдельные организационные структуры. Это мы видели на примере Scrum of Scrum, который организует две структуры управления – продуктовую и организационную, иногда дополняемую третьей, технологической. Более сложной конструкцией является Spotify фреймворк, который заслуживает отдельного рассмотрения.
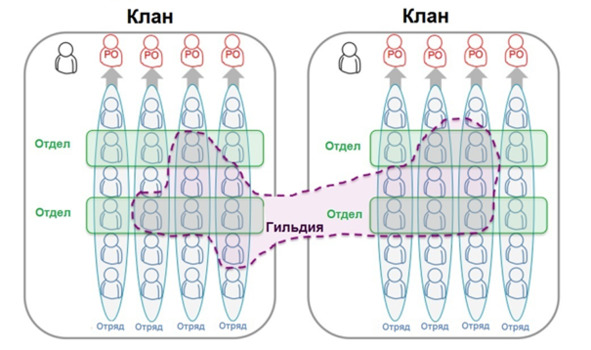
Основной производственной единицей в ней является клан (tribe) в 100—200 человек, который работает над отдельным продуктом. Он представляет собой матрицу: делится на кроссфункциональные производственные отряды (squad) и функциональные отделы (chapter). Отряды реализуют новый функционал и состоят из специалистов разных специализаций, которые дополняют друг друга. А отделы координируют работы специалистов из разных команд, использующих общие технологии, решая такие задачи, как разработка мобильных интерфейсов в едином стиле, однородная работа серверной части или развитие технологий тестирования. Отметим, что отделы работают над применением технологий в рамках продукта, а вот для развития технологий в целом по компании существуют еще гильдии (guild) по интересам. По мере роста компании над кланами появились структуры следующего уровня – альянсы (alliance) и бизнес-единицы (business unit).
Конструкция – очень сложная и многоплановая и во многом обусловленная контекстом компании. Spotify ей делится, но с предостережением: «используйте наши опыт, но не пытайтесь тупо скопировать, оно не взлетит, мы это точно знаем, потому что у нас самих конструкция развивается и растет». Но много попыток именно механического копирования, обычно неудачных. А вот идеи заложены плодотворные.
При этом в самой компании Spotify организационная структура развивается очень быстро. И я хочу интересующимся порекомендовать доклад Yuliya Kurapatenkava на Saint TeamLeadConf-2018, в котором она рассказывала про логику развития (мой конспект есть в отчете с конференции, а сам доклад по-английски). И вы можете сравнить то, что звучит в докладе с тем описанием фреймворка, которое доступно по ссылке в начале раздела и фиксирует состояние несколько лет ранее.

Пересборка организации
Здесь стоит рассмотреть практическое применение подобных фреймворков. Один продукт, над которым работают несколько команд, далеко не всегда означает единственный продукт в смысле софта, более того, часто речь идет об одном бизнес-продукте, поддержка которого со стороны софта требует общей серверной части и нескольких приложений на разных платформах – web и мобильных. Естественным образом для того, чтобы какой-то новый функционала стал доступен конечным пользователям, он часто должен быть реализован в серверной части и для каждой из платформ. И тут может быть два подхода: сделать команды, каждая из которых сосредоточенна вокруг каждого софтверного продукта, при этом только она работает с кодовой базой продукта и отвечает за его архитектуру. В этом случае для организации могут применяться фреймворки, подобные LeSS.
Однако, то что задача по реализации нового функционала делится на несколько, каждую из которых выполняет своя команда, сильно увеличивает количество необходимых синхронизаций и время разработки. Поэтому часто применяется и другой способ организации, кросс-функциональные команды, включающие специалистов по всем приложениям и делают все доработки для новой фичи. При этом возникает общее владение кодом, и надо дополнительно принимать меры для удержания целостности архитектуры каждого приложения, а также обучения и передачи опыта, потому что внутри команды такие специалисты не могут учиться. И это получается структура, похожая на клан в Spotify.
Так вот, в зависимости от потока задач и этапа развития компании предпочтительная структура может сильно изменяться. И сейчас IT-компании умеют достаточно быстро и успешно перестраивать свою структуру в зависимости от потребностей развития продукта. Я хочу сослаться на опыт ivi. На TeamLeadConf-2018 Евгений Россинский рассказывал как они обеспечивали целостность продуктов и поддерживали знания разработчиков при переходе к кроссфункциональным командам от команд, собранных вокруг отдельных приложений. А через год TeamLeadConf-2019 он же рассказывал как за год они для решения задач реинжиниринга ядра продукта вернулись к командам, организованным по приложениям, провели реинжиниринг, а затем – снова перешли к кросс-функциональным командам. Компания ivi предоставляет чистый цифровой продукт. Однако, похожая бизнес-структура сейчас характерна и для банков и для туроператоров, потому что их продукты сейчас все больше и больше перемещаются в цифровую сферу. Но, насколько я знаю, быстро пересобираться таким образом они еще не умеют, да и для IT опыт ivi является передовым. И, думаю, это может дать хорошее представление о том, какова она – динамично развивающаяся и перестраивающаяся современная цифровая компания, насоклько быстро она умеет изменяться.
Сложные фреймворки – SAFe и Enterprise Scrum
Scaled Agile Framework (SAFe) является самым сложным Agile-фреймворком, но при этом – самым популярным. Это сложная конструкция уровня компании с управлением потоками создания ценности и архитектурой. На мой взгляд, популярность этого фреймворка сродни популярности PMBOK или RUP – в нем есть все и на все случаи жизни, и предлагается просто взять нужное. Кстати, автором фреймворка является Дин Леффингуэлл (Dean Leffingwell), один из авторов RUP.
И, на мой взгляд, это – неработоспособная конструкция, хотя и привлекательная в своем инженерном совершенстве. Фреймворк не будет работать по тем же самым причинам – его сложность превышает разумный предел, при этом обвинить сам фреймворк будет невозможно, всегда окажется, что это вы не смогли его правильно реализовать. И дело не только в сложности фреймворка: SAFe пытается за счет сложных регламентов превратить запутанную область в сложную, а это – невозможно. Подробнее о сложности областей – в описании Кеневин-фреймворка в главе «Место Agile-команд в компании».
Вместе с тем, в силу популярности и привлекательности есть много проектов внедрения SAFe. B эти проекты часто несут позитивный эффект, как и многие проекты внедрения проектного управления. В процессе внедрения компания разбирается с тем, как устроены ее цепочки создания ценности. Таким образом, появляется структурированное описание деятельности компании, при чем не на уровне процессов, а через цепочки создания ценности, что представляет собой значительное методологическое продвижение вперед.
Другая выгода, общая для внедрения большинства Agile-фреймворков – разрушение застывшей бюрократической структуры, разморозка коммуникаций и инициативы в компании. Но она часто уже достигнута, так как до глобальной реорганизации компании через внедрения SAFe следует этап внедрения Scrum или других Agile-методов на уровне отдельных команд. Впрочем, уровень отдельных команд в SAFe тоже специфицирован, там как раз Scrum или Kanban, а вот над ними – несколько уровней управления компанией.

Довольно интересен фреймворк Enterprise Scrum предлагает переход от создания IT-продукта к поставке ценности, управляемой набором связанных метрик. К сожалению, в отличие от всего остального он не завершен. Его создатель Mike Beedle, кстати, один из авторов Agile-манифеста был, к сожалению убит в Чикаго весной 2018 года, и работа не завершена. Однако, на сайте есть достаточно подробная конструкция системы метрик, совместимая с Agile-методами управления, и, возможно, она вам окажется полезной при конструировании собственной, хотя в готовом виде ее, естественно, брать не стоит.

Кейсы Agile-трансформации.
Часть 1 – банки
По опыту лекций об Agile в разных аудиториях, рассмотрение кейсов Agile-трансформации вызывает большой интерес слушателей. В том числе – таких известных, как Agile в Сбербанке или Альфа-банке, хотя, казалось бы, об этом можно найти много публичных материалов. Причина, думаю, в том, что хорошие системные материалы погребены под большим количеством попсовых изложений, которые не раскрывают суть, а иногда ее искажают. Поэтому я начинаю рассказ о кейсах, чтобы в совокупности дать многовариантную картину. Сейчас речь пойдет о трансформации банков, причем не IT-подразделений, а работы бизнеса в целом.
Мои источники – доклады на профильных конференциях – AgileDays, Agile Business и других, а также разговоры в кулуарах конференций и другие частные разговоры. Там, где это возможно, в статье будут ссылки на конкретные доклады. По конференциям я публикую отчеты на моем сайте, и конспекты большинства упомянутых здесь докладов есть в отчетах с соответствующих конференций. Однако, в любом случае все написанное – моя собственная интерпретация услышанного из разных источников. Она не претендует на истину в последней инстанции, и если у вас другая картина, вы можете ей поделиться. Вместе с тем, хочу отметить, что авторы докладов, которые тоже читали мои отзывы, обычно не опровергают моей интерпретации, а в тех случаях, когда они указывают на необходимость исправлений, я обычно это делаю.+ Disclaimer: все изложенное – моя личная интерпретация событий
Сберджайл
Итак, начну я с истории Agile-трансформации Сбербанка. Публичным началом этой истории является выступление Германа Грефа на Гайдаровском форуме-2016, которое существенно повлияло на распространение Agile-методов в России и заслуживает отдельного анализа. В изложениях выступления фокус был на то, что «Греф назвал Россию страной-дауншифтером», в то время как реальным сообщением была необходимость перестройки госсистем, и особенно образования, если Россия не хочет оказаться в числе стран-дауншифтеров (07:40—12:00). Это как раз к вопросу о том, почему полезно смотреть первоисточники, а не изложения СМИ. Но в контексте этой статьи интересно то, что говорится дальше.
